|
亙峫偊側偄抦擻#3亜丂
崱夞偼丄慜夞偺乽嫮壔妛廗乿偺懕偒偱偡丅
儅僢僠敔偱偱偒偨擼偑丄峴偔愭乆偱暘偐傟摴偑偁傞嶳摴傪丄
僩儔僀傾儞僪僄儔乕偱曕偒夞傝側偑傜丄
僑乕儖乮嶳捀乯傑偱偺摴傪妎偊偰偄偒傑偡丅
偙偙偱偼丄嶳捀傊偺儖乕僩偲偄偆椺戣偵側偭偰偄傑偡偑丄
傛偔僥儗價側傫偐偱尒傞
乽偹偢傒偼柪楬傪妎偊傜傟傞偐乿揑側
壽戣偲摨偠偩偲偍傕偭偰偔偩偝偄丅
埲壓丄乽儅僢僠敔偺擼乿偺乽僯儏乕儔儖僱僢僩儚乕僋乿傛傝敳悎
仭儅僢僠敔嫮壔妛廗
仠柪偄摴偔偹偔偹
偝偰丄嬶懱揑偵偼嫮壔妛廗朄偼
偳偺傛偆偵偟偰妛廗偟偰偄偔傕偺側偺偱偟傚偆偐丅
戝奣偺応崌丄偁傞応柺偱偳偆偟偰偄偄偐擸傓偲偄偆偙偲偼丄
偮傑傝偄偔偮偐偺慖戰巿偑偁偭偰丄
偳傟傪慖傫偩傜偄偄偺偐擸傓偲偄偆偙偲偩偲巚偄傑偡丅
嫮壔妛廗朄偱偼丄奺応柺偵偮偒丄
偦偆偄偆慖戰巿偑偄偔偮傕偁傞丅
偦偟偰偦偺帪揰偱偼丄偳偺慖戰偑惓偟偄偐傢偐傜側偄丅
偦偆偄偆忬嫷傪憐掕偟偰丄妛廗傪巒傔傑偡丅
愭傎偳偺嶳搊傝偺榖傪椺偵庢偭偰尒偰偄偒傑偟傚偆丅
偦偟偰丄偙偙偱傕儅僢僠敔偲儅僢僠朹傪搊応偝偣偰丄
妛廗偺夁掱傪懱尡偟偰傒偰傕傜偆偙偲偵偟傑偡丅
乗乗尒抦傜偸嶳摴傪曕偄偰偄傞丅
栚昗偼丄嶳捀偵偨偳傝拝偔偙偲偩偲偟傑偟傚偆丅
栚昗偵摓払偡傟偽惉岟丄
峴偒巭傑傝偵側偭偰偟傑偭偨傜幐攕偲偟傑偡丅
仩梡堄偡傞摴嬶
仧儅僢僠敔丂丂丂丂8敔
仧儅僢僠朹丂丂丂丂奺敔4杮
仧8柺懱僒僀僐儘丂 1偮
仩弨旛
抧恾偼埲壓偺傛偆偵寛傔傑偡丅
暘婒揰偼4偮偱丄奺暘婒揰偱偼摴偼
嵍塃2枖偵暘偐傟偰偄傑偡丅
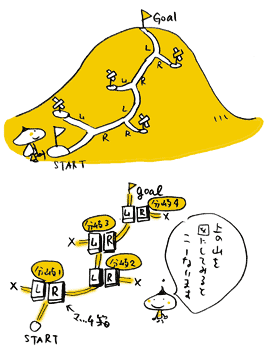
儅僢僠敔偼丄奺暘婒揰偺奺摴偺忋偵
2屄偢偮暲傋偰抲偒傑偡丅
偦偟偰丄奺儅僢僠敔偵偼丄
嵟弶4杮偢偮儅僢僠朹傪擖傟偰偍偒傑偡丅
奺暘婒揰偺儅僢僠敔偺偆偪丄
塃偵抲偐傟偨儅僢僠敔偼
塃偺摴偵峴偔偙偲傪恑傔傞儅僢僠敔乮儅僢僠敔俼乯丄
嵍偵抲偐傟偨儅僢僠敔偼
嵍偺摴偵峴偔偙偲傪恑傔傞儅僢僠敔乮儅僢僠敔俴乯偱偡丅
弨旛偼埲忋偱偡丅
仠塃偐嵍偐乧乧
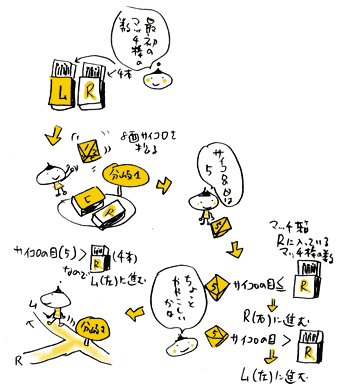
偝偰丄偄傛偄傛偲嶳捀偵岦偐偭偰偺椃偺僗僞乕僩偱偡丅
奺暘婒揰偱嵍塃偳偪傜偵恑傓偐偼丄
奺暘婒揰偵抲偐傟偨2偮偺儅僢僠敔偺拞偺儅僢僠朹偺悢偲丄
僒僀僐儘偺栚偺娭學偐傜寛傑傝傑偡丅
傑偢丄僒僀僐儘傪怳傝傑偡丅
僒僀僐儘偺栚偑丄儅僢僠敔俼偺儅僢僠朹偺悢偲摨偠偐丄
偦傟埲壓側傜塃曽岦傊恑傒丄
偦傟埲忋偩偭偨傜丄嵍曽岦傊恑傒傑偡丅
嵟弶丄塃曽岦儅僢僠敔偺儅僢僠朹偺悢偼4杮偱偡偐傜丄
僒僀僐儘偺栚偑4傑偱偩偭偨傜塃傊恑傓丄
偦偆偱側偗傟偽嵍傊恑傓偙偲偵側傝傑偡丅
摨條偵丄儅僢僠敔俼偺儅僢僠朹偺悢偼2杮偩偭偨傜丄
僒僀僐儘偺栚偑2傑偱偩偭偨傜塃偵恑傓丄
偦偆偱側偗傟偽嵍偵恑傓偙偲偵側傝傑偡丅
仠偝偭偦偔恑傫偱傒傞
傑偢僒僀僐儘傪怳傝傑偡丅
僒僀僐儘偺栚偼5偩偭偨偲偟傑偟傚偆丅
嵟弶丄偳偺儅僢僠敔偵傕儅僢僠朹偼4杮偱偟偨偐傜丄
亙僒僀僐儘偺栚亜儅僢僠敔俼偺儅僢僠朹偺悢偲側傝丄
寢壥丄暘婒揰1偱偼嵍曽岦傊恑傓偙偲偵側傝傑偟偨丅
恾傪尒偰偄偨偩偗傟偽傢偐傞傛偆偵丄
暘婒揰1偱嵍曽岦偵恑傓偲峴偒巭傑傝偱偡丅
偙偺傛偆偵丄峴偒巭傑傝偵擖偭偰偟傑偭偨傜
偦偺夞偺朻尟偼廔椆偱偡丅
媡偵丄峴偒巭傑傝偵峴偔偐丄
嶳捀偵偨偳傝拝偔傑偱偼朻尟偑懕偗傜傟傑偡丅
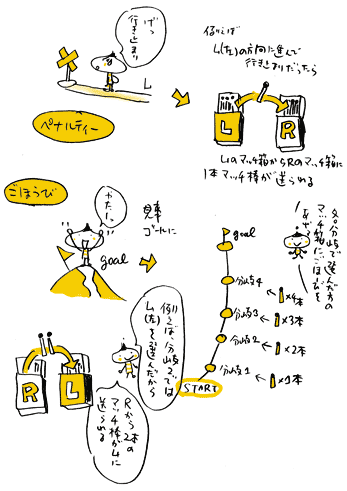
仠儁僫儖僥傿乕偲偛朖旤
偝偰丄朻尟偑廔椆偟偨傜丄曌嫮僞僀儉偱偡丅
朻尟偑廔椆偡傞偲偄偆偙偲偼丄峴偒巭傑傝偵峴偭偨偐丄
嶳捀偵偨偳傝拝偄偨偐偺偄偢傟偐偱偡丅
峴偒巭傑傝偵峴偭偨傜儁僫儖僥傿乕傪梌偊丄
嶳捀偵偨偳傝拝偄偨傜偛朖旤傪梌偊偰傗傝傑偡丅
傑偢丄儁僫儖僥傿乕偺儖乕儖偱偡丅
忋偺椺偱偼丄暘婒揰1偱嵍曽岦傪慖傫偩偨傔丄
峴偒巭傑傝偵峴偭偰偟傑偄傑偟偨丅
傛偭偰丄暘婒揰1偱嵍曽岦偵恑傓偙偲傪恑傔偨
儅僢僠敔俴偵儁僫儖僥傿乕偑梌偊傜傟傑偡丅
儁僫儖僥傿乕偲偟偰丄
儅僢僠敔俴偺拞偺儅僢僠朹1杮傪儅僢僠敔俼偵搉偟傑偡丅
偙偺寢壥丄
儅僢僠敔俴偵偼3杮偺儅僢僠朹丄
儅僢僠敔俼偵偼5杮偺儅僢僠朹偲側傝傑偟偨丅
偙偺傛偆偵丄
峴偒巭傑傝偵峴偐偣偰偟傑偭偨
儅僢僠敔偺儅僢僠朹偑1杮尭傜偝傟丄
堦曽偺儅僢僠敔偵梌偊傜傟傞偺偑儁僫儖僥傿乕偲側傝傑偡丅
師偵偛朖旤偺愢柧偱偡丅
偛朖旤偼僑乕儖偵偨偳傝拝偄偨偲偒偩偗偵梌偊傜傟傑偡丅
儁僫儖僥傿乕偲摨偠儖乕儖偲側傞偲丄
暘婒揰4偵偍偄偰嵍偺摴傪慖偽偣偨
儅僢僠敔俴偩偗偑偛朖旤傪梌偊傜傟偦偆偱偡偑丄
偦偆偱偼偁傝傑偣傫丅
暘婒揰4偵偍偄偰嵍偺摴傪慖偽偣偨岟愌偺堿偵偼丄
暘婒揰3偱塃曽岦傪慖傫偩偙偲丄
暘婒揰2偱嵍曽岦傪丄暘婒揰1偱塃曽岦傪慖傫偩偙偲偺
庤暱傕偁傞偼偢偱偡丅
偱偡偐傜丄偛朖旤偺応崌偵偼
偦傟傜偺慖戰偵傕暘偗慜偑梌偊傜傟傑偡丅
偩偐傜偲偄偭偰丄暘婒揰1偱塃曽岦傪慖傫偩帪揰偱丄
偦偺慖戰傪昡壙偡傞偙偲偼偱偒傑偣傫丅
傑偩偦偺帪揰偱偼寢壥偑弌偰偄側偄偐傜偱偡丅
崱偼抧恾偑嵟弶偐傜傢偐偭偰偄傑偡偐傜丄
嵟弶偐傜偱傕偛朖旤傪偁偘傜傟傑偡偑丄
抧恾偑側偐偭偨偲偟偨傜丄
偦傟偑惓偟偄慖戰偐偳偆偐傢偐傝傑偣傫偐傜偹丅
偱偡偐傜丄嶳捀偵偨偳傝拝偄偰偐傜丄
弶傔偰偦傟傑偱偺暘婒揰偱偺慖戰偵
偛朖旤偑梌偊傜傟傞偺偱偡丅
偙傟偑忋偱尵偭偨
乽堦偮偺応柺偱堦偮偺峴摦傪庢偭偨偗傟偳丄
丂偦偺帪揰偱偼丄偦傟偑偄偄偺偐丄
丂埆偄偺偐敾抐偑偱偒側偄偲偄偆応崌乿
偵懳偡傞懳張曽朄偲偄偆偙偲偵側傝傑偡丅
偝偰丄偛朖旤偺暘攝偱偡偑丄
偡傋偰偺暘婒揰偱偺慖戰偑摨偠壙抣偑偁偭偨偐偲偄偆偲丄
偙傟偼媈栤偱偡丅
偙偺応崌偼丄僐乕僗偑扨弮側偺偱丄
偦傟偱傕栤戣偼側偄偱偟傚偆偑丄
堦斒揑偵嵟屻偺慖戰偑偨偔偝傫偛朖旤傪傕傜偊丄
偦偺1偮慜偼偦傟傛傝彮側偔丄
偦傟傛傝慜偼傕偭偲彮側偔偲丄
偩傫偩傫偲彮側偔側偭偰偄偔曽偑帺慠側傛偆側婥偑偟傑偡丅
偦偙偱丄暘婒揰4偱偼丄
儅僢僠敔俴偵偛朖旤偲偟偰儅僢僠朹4杮丄
暘婒揰3偱偼丄
儅僢僠敔俼偵偛朖旤偲偟偰儅僢僠朹3杮乧乧
偲偄偭偨嬶崌偵偛朖旤偺検傪尭傜偟偰偄偒傑偡丅
偦偆偦偆丄偳偙偐傜偛朖旤傪傕傜偆偐偱偡偑丄
偙傟偼儁僫儖僥傿乕偺偲偒偲摨偠丄
傕偆堦曽偺儅僢僠敔偐傜傕傜偄傑偡丅
暘婒揰4偱偼儅僢僠敔俼偐傜
4杮偺儅僢僠朹偑儅僢僠敔俴偵搉偝傟傑偡丅
儁僫儖僥傿乕偲偛朖旤偺儖乕儖偼埲忋偱偡丅
偨偩偟丄椺偊偽4杮傕傜偍偆偲巚偭偰傕丄
憡庤偺儅僢僠敔偵3杮埲壓偟偐側偄応崌偼丄
偦傟偱偁偒傜傔傞偟偐偁傝傑偣傫丅
仠埲忋傪孞傝曉偡
偝偰丄儅僢僠敔嫮壔妛廗曽朄偺妛廗曽朄偼丄
偨偭偨偙傟偩偗偱偡丅
偙傟傪孞傝曉偡偙偲偱丄
偩傫偩傫偲惓偟偄儖乕僩傪恑傔傞傛偆偵側偭偰偄偒傑偡丅
椺偊偽丄嵟弶偵暘婒揰1偱嵍偵恑傫偩偨傔偵丄
暘婒揰1偺儅僢僠敔俴偺儅僢僠朹偼
3杮偵側偭偰偟傑偄傑偟偨丅
偙偺寢壥丄師偵僒僀僐儘偺栚偑
嵟弶偲摨偠5偱偁偭偨応崌偱傕丄
僒僀僐儘偺栚亖儅僢僠敔俼偺儅僢僠朹偺悢偲側傝丄
崱搙偼塃曽岦偵恑傓偙偲偑偱偒傞傛偆偵側傝傑偡丅
傕偪傠傫丄僒僀僐儘偺栚偑7傗8偩偭偨傜丄
憡曄傢傜偢嵍曽岦偵恑傫偱偟傑偄傑偡偑丄
儁僫儖僥傿乕傪孞傝曉偟梌偊傜傟傞偆偪偵丄
儅僢僠敔俴偺儅僢僠朹偼0杮丄
偮傑傝儅僢僠敔俼偺儅僢僠朹偼8杮偵側傝丄
僒僀僐儘偺栚偑側傫偱偁傟丄
昁偢塃曽岦偵恑傓偙偲偵側傞丅
偮傑傝暘婒揰1偱偼塃曽岦偵恑傓偙偲傪妎偊偨丄
偦偆側傞傢偗偱偡丅
丂
埲忋偑丄嫮壔妛廗朄偺戝偞偭傁側巇慻傒偱偡丅
旕忢偵娙扨側巇慻傒偱偡傛偹丅
仠嫮壔妛廗朄偺庛揰
嫮壔妛廗朄偼崅搙偺悇榑丄敾抐丄婰壇側偳偲偄偆
執偦偆側擻椡偼帩偨側偄偺偱偡偑丄
偦傟偱傕丄帋峴嶖岆傪孞傝曉偡偩偗偱
偆傑偔栤戣傪夝寛偟偰偟傑偄傑偡丅
偙偆偟偨偙偲偐傜丄
偙偺傛偆側儃僩儉傾僢僾側峫偊曽偙偦偑丄
崱屻偺AI偺惓偟偄偁傝曽偱偼側偄偐偲偄偆
堄尒傕偁傝傑偡丅
傕偪傠傫丄傑偩傑偩栤戣揰傕巆偭偰偄傑偡丅
壗傪惉岟偲偡傞偐丄
曬廣偺暘攝曽朄傪偳偆偡傞偐側偳傪寛傔崬傓偲側傞偲丄
寢峔栵夘側栤戣偲側傞偺偱偡丅
傑偨丄幚嵺偺栤戣偱偼
嫮壔妛廗偱昁梫側乽帋峴嶖岆乿偑
嫋偝傟側偄応崌傕偁傝傑偡丅
椺偊偽儘儃僢僩偵慻傒崬傫偩応崌側偳偼丄
帋峴嶖岆傪孞傝曉偟偰偄傞偲丄
枮懌側妛廗傪偡傞慜偵
夡傟偰偟傑偆傫偠傖側偄偐側偳偲偄偆怱攝傕偁傝傑偡丅
|


